J’ai déjà traité plusieurs fois de l’utilisation d’expressions régulières dans des instructions SQL, et notamment dans
ce billet.
Je vais cette fois étudier le problème de manière systématique.
Pour quelques explications concernant les expressions régulières, voir
ce billet.
Dans la table PostgreSQL dépenses (déjà rencontrée
ici mais le contenu a changé depuis lors), je recherche les rangées dont la colonne détails contient le mot 'jardin'.
Travaillant dans un terminal psql, je lance l’instruction qui convient, utilisant la fonction regexp_matches :
bdtest=> select référence, montant, détails,
bdtest-> regexp_matches(détails, 'jardins')
bdtest-> from dépenses
bdtest-> order by référence
bdtest-> ;
référence | montant | détails | regexp_matches
-----------+---------+---------------------+----------------
2013-0014 | 103,00 | Docteur Desjardins | {jardins}
2013-0023 | 40,00 | Station des jardins | {jardins}
2017-0045 | 173,24 | Les jardins arborés | {jardins}
(3 rows)
Très bien mais une clause
where détails like '%jardins%'
aurait aussi bien fait l’affaire sauf que regexp_matches donne la possibilité d'utiliser des expressions régulières offrant donc plus de souplesse.
Ainsi si je remplace 'jardins' par '\yjardins\y', la rangée 2013-0014 va disparaître du résultat car dans une expression régulière \y indique une bordure de mot.
(Les bordures de mot sont habituellement indiquées par \b, mais pas selon le standard suivi par PostgreSQL)
La fonction substring permet elle aussi l'utilisation d'expressions régulières, mais elle nécessite l'utilisation d'une clause where si on veut exclure du résultat les rangées qui ne satisfont pas au critère.
Exemple :
select référence, montant, détails,
substring(détails, '\yjardins\y')
from dépenses
where substring(détails, '\yjardins\y') is not null
order by référence
;
référence | montant | détails | substring
-----------+---------+---------------------+-----------
2013-0023 | 40,00 | Station des jardins | jardins
2017-0045 | 173,24 | Les jardins arborés | jardins
(2 rows)
A l'inverse avec regexp_matches, il faut utiliser un subselect pour afficher toutes les rangées :
bdtest=> select référence, montant, détails,
bdtest-> (select regexp_matches(détails, '\yjardins\y'))
bdtest-> from dépenses
bdtest-> order by référence
bdtest-> ;
référence | montant | détails | regexp_matches
-----------+---------+----------------------+----------------
2013-0014 | 103,00 | Docteur Desjardins |
2013-0015 | 56,47 | Courrefar |
2013-0016 | 49,56 | Station des camélias |
2013-0017 | 117,23 | Caro |
2013-0018 | 43,00 | Docteur Lebon |
2013-0019 | 245,74 | La marmite |
2013-0020 | 24,53 | Phie Arcodor |
2013-0021 | 104,25 | Aupré |
2013-0022 | 68,17 | Courrefar |
2013-0023 | 40,00 | Station des jardins | {jardins}
2014-0016 | 87,23 | Caro |
2014-0017 | 30,00 | Docteur Ledoux |
2014-0018 | 149,57 | La bonne auberge |
2014-0019 | 50,00 | Station Les cafés |
2017-0045 | 173,24 | Les jardins arborés | {jardins}
(15 rows)
Recherchons les mots de 7 lettres minuscules :
bdtest=> select référence, montant, détails,
bdtest-> regexp_matches(détails, '\y[[:lower:]]{7}\y', 'g')
bdtest-> from dépenses
bdtest-> order by référence
bdtest-> ;
référence | montant | détails | regexp_matches
-----------+---------+---------------------+----------------
2013-0019 | 245,74 | La marmite | {marmite}
2013-0023 | 40,00 | Station des jardins | {jardins}
2014-0018 | 149,57 | La bonne auberge | {auberge}
2017-0045 | 173,24 | Les jardins arborés | {jardins}
2017-0045 | 173,24 | Les jardins arborés | {arborés}
(5 rows)
Je rappelle que \y indique une bordure de mots. Celui-ci doit comporter 7 caractères de la classe [[:lower:]]. Nous utilisons cette classe plutôt que la classe [a-z] qui ne comprend pas les caractères accentués.
L’option facultative ‘g’ indique à la fonction regexp_matches d’afficher toutes les occurrences du motif recherché et non pas seulement la première. C’est pourquoi la rangée '2017-0045' apparaît deux fois.
La donnée renvoyée par la fonction regexp_matches est une donnée de type 'array' contenant une ou plusieurs données de type texte.
Mettons cela en évidence :
bdtest=> select référence, montant, détails,
bdtest-> regexp_matches(détails, '\y([[:lower:]]{3})([[:lower:]]{4})\y')
bdtest-> from dépenses
bdtest-> order by référence
bdtest-> ;
référence | montant | détails | regexp_matches
-----------+---------+---------------------+----------------
2013-0019 | 245,74 | La marmite | {mar,mite}
2013-0023 | 40,00 | Station des jardins | {jar,dins}
2014-0018 | 149,57 | La bonne auberge | {aub,erge}
2017-0045 | 173,24 | Les jardins arborés | {jar,dins}
(4 rows)
Le motif est découpé en deux à l'aide de parenthèses ce qui conduit à des tableaux à deux éléments.
De telles parenthèses (dites mémorisantes) sont utiles quand on envisage de procéder au remplacement de la chaîne trouvée. Dans la chaîne de remplacement, \1, \2, …, correspondent aux différents morceaux de la chaîne d'origine qui sont entre parenthèses.
Illustrons le en utilisant la fonction regexp_replace :
bdtest=> select référence, montant,
bdtest-> regexp_replace(détails, '\y([[:lower:]]{3})([[:lower:]]{4})\y', '\2\1', 'g')
bdtest-> from dépenses
bdtest-> order by référence
bdtest-> ;
référence | montant | regexp_replace
-----------+---------+----------------------
2013-0014 | 103,00 | Docteur Desjardins
2013-0015 | 56,47 | Courrefar
2013-0016 | 49,56 | Station des camélias
2013-0017 | 117,23 | Caro
2013-0018 | 43,00 | Docteur Lebon
2013-0019 | 245,74 | La mitemar
2013-0020 | 24,53 | Phie Arcodor
2013-0021 | 104,25 | Aupré
2013-0022 | 68,17 | Courrefar
2013-0023 | 40,00 | Station des dinsjar
2014-0016 | 87,23 | Caro
2014-0017 | 30,00 | Docteur Ledoux
2014-0018 | 149,57 | La bonne ergeaub
2014-0019 | 50,00 | Station Les cafés
2017-0045 | 173,24 | Les dinsjar orésarb
(15 rows)
regexp_replace renvoie une chaîne inchangée si le motif n'est pas trouvé.
L'option facultative 'g' a la même signification qu'auparavant. En son absence, on aurait pour la rangée '2017-0045' le texte : 'Les dinsjars arborés'.
Je vais maintenant donner un exemple pratique d'utilisation de ces fonctions.
Considérons une table (par exemple mvts) reprenant les mouvements effectués sur un compte en banque. La banque fournit quantité de données (date, montant etc), mais pas directement le numéro de compte de la contrepartie. Aussi quand de nouvelles rangées sont créées lors de l'importation des données fournies, les éléments de la colonne 'compte' prévue pour contenir le numéro de compte sont null ou vides. Cependant ce numéro de compte se trouve parfois perdu au milieu du texte informatif se trouvant dans un champ souvent appelé 'détails', jamais à la même place et parfois sous des formats différents.
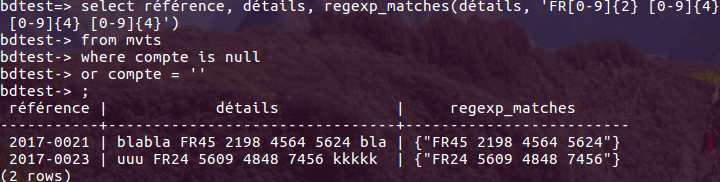
L' instruction SQL
select référence, détails, regexp_matches(détails, 'FR[0-9]{2} [0-9]{4} [0-9]{4} [0-9]{4}')
from mvts
where compte is null
or compte = ''
permet de repérer certains de ces comptes.
En image :
Il reste à mettre le champ compte à jour, mais il ne faut pas oublier que le retour de regexp_matches n'est pas du texte. Il faut d'abord le transformer. L'instruction update est donc :
update mvts
set compte = substr(regexp_matches(détails, 'FR[0-9]{2} [0-9]{4} [0-9]{4} [0-9]{4}')::text, 3, 19)
where compte is null
or compte = ''
Il n'y a pas de mise à jour si le motif n'est pas rencontré.
On pourrait utiliser la fonction substring à condition d'adapter la clause where afin d'éviter les mises à jour indésirables:
update mvts
set compte = substring(détails,'FR[0-9]{2} [0-9]{4} [0-9]{4} [0-9]{4}')
where (compte is null
or compte = '')
and substring(détails,'FR[0-9]{2} [0-9]{4} [0-9]{4} [0-9]{4}')
is not null
Les comptes figurant dans 'détails' peuvent se trouver sous un autre format.
L'instruction pour les retrouver doit être adaptée :
select référence, détails, regexp_matches(détails, 'FR[0-9]{14}')
from mvts
where compte is null
or compte = ''
En images le résultat:
L'instruction 'update' est elle aussi modifiée :
update mvts
set compte = substr(regexp_matches(détails, 'FR[0-9]{14}')::text, 2, 16)
where compte is null
or compte = ''
Le problème est que maintenant les comptes se trouvent dans la table mvts sous deux formats différents.
Qu'à cela ne tienne : la fonction regexp_replace nous permet de remettre tout ça en place :
update mvts
set compte = regexp_replace(compte, '(FR[0-9]{2})([0-9]{4})([0-9]{4})([0-9]{4})', '\1 \2 \3 \4')
where compte <> regexp_replace(compte, '(FR[0-9]{2})([0-9]{4})([0-9]{4})([0-9]{4})', '\1 \2 \3 \4')
Le motif est scindé en 4 morceaux à l'aide de parenthèses mémorisantes. Dans la chaîne de remplacement ces morceaux (\1, \2, ...) sont séparées par des espaces. La clause where empêche les mises à jour inutiles (compte inchangé) : en effet regexp_replace retourne le compte d'origine si le motif n'est pas trouvé.
Les numéros de compte peuvent se trouver sous d'autres formats que ceux indiqués dans ces exemples.
Il faut évidemment adapter les expressions régulières en conséquence.
Si on utilise une table 'comptes' qui comprend la clef primaire 'compte', il reste à insérer des rangées pour les comptes de mvts qui n'existent pas dans cette table. Ceci peut se faire avec l'instruction :
insert into comptes
(compte)
select distinct a.compte
from mvts a natural left outer join comptes b
where b.compte is null
and a.compte > ''
Lorsque la colonne a.compte contient une valeur qui n'existe pas dans la table comptes, le système joint à la rangée de la table mvts une rangée fictive de la table comptes dont tous les champs sont à la valeur NULL (pour des informations sur les différents type de
join voir
ici).
La clause where permet donc d'afficher la liste des comptes présents dans mvts et qui n'existent pas dans la table comptes.
Pour être complet, signalons l'existence des deux fonctions regex_split_to_array et regexp_split_to_table. L'expression régulière sert alors de délimitateur.
Illustrons :
Dans ces instructions la fonction regexp_replace de la clause where est inopérante (la chaîne de remplacement pourrait être n'importe quoi) : elle sert simplement à éliminer les rangées sans le mot 'des' dans détails car les fonctions regexp_split retournent toujours quelque chose même si l'expression régulière n'est pas trouvée.
Montrons le:
Ces fonctions n'admettent pas les options du genre 'g'.
Note: on pourrait dans les 2 premières des 4 instructions précédentes utiliser
where substring(détails, '\ydes\y') is not null
au lieu de
where détails <> regexp_replace(détails, '\ydes\y', '')