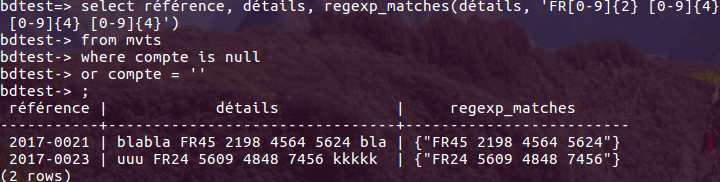
La table utilisée s'appelle bcard, mais tout ce qui suit est valable quelle que soit la table pourvu que celle-ci contienne une colonne date et une colonne numérique.
Si date_exec est une date, to_char(date_exec, 'TMMonth') affichera une chaîne de caractère contenant le nom du mois de cette date. Une clause 'Order by date_exec' dans un query SQL provoquera l'apparition du nom des mois dans leur ordre naturel.
Si on effectue un regroupement par mois, une telle clause n'a aucun sens et l'exécution du query donnera une erreur.
Pour avoir les mois dans le bon ordre, on peut utiliser la fonction to_char(date_exec, 'MM TMMonth'): chaque mois sera alors précédé de son numéro d'ordre.
Je veux faire disparaître ce numéro. Je peux alors utiliser awk où la fonction SQL substr (voir l'article précédent)
Un query ressemblant à celui-ci
select substr(to_char(date_exec, 'MM TMMonth'), 4) AS mois,
sum (montant) AS total
from bcard
where extract(year from date_exec) = 2013
group by to_char(date_exec, 'MM TMMonth')
order by to_char(date_exec, 'MM TMMonth')
Cependant si je désire avoir aussi les différents montants qui constituent le total de chaque mois avec un query tel que celui-ci:
select substr(to_char(date_exec, 'MM TMMonth'), 4) AS mois,
sum (montant) AS total
from bcard
where extract(year from date_exec) = 2013
UNION
select substr(to_char(date_exec, 'MM TMMonth'), 4),
sum (montant)
from bcard
where extract(year from date_exec) = 2013
group by to_char(date_exec, 'MM TMMonth')
order by to_char(date_exec, 'MM TMMonth')
je rencontre de nouveau une erreur:
ERROR: column "bcard.date_exec" must appear in the GROUP BY clause or be used in an aggregate function
LINE 1: select substr(to_char(date_exec, 'MM TMMonth'), 4) AS mois,
^
A moi awk!
Après avoir enlevé les 'substr', je complète mon query en ajoutant une colonne pour montrer les dates des opérations ainsi qu'une colonne qui contiendra les mentions 'SOUS-TOTAL' et 'TOTAL' car une troisième instruction 'SELECT' me fournira le total général.
Au final le query est le suivant:
select to_char(date_exec, 'MM TMMonth') AS mois,
'' as " ", date_exec::text,
montant
from bcard
where extract(year from date_exec) = 2013
UNION
select to_char(date_exec, 'MM TMMonth'),
'SOUS-TOTAL', '',
sum (montant) AS total
from bcard
where extract(year from date_exec) = 2013
group by 1, 2, 3
UNION
select '99', 'TOTAL', '', sum(montant)
from bcard
order by 1, 2, 3
Les colonnes correspondantes des différents 'select' doivent avoir le même type de données. Si la colonne 3 du premier 'select' contient des dates, il doit en être de même pour les autres 'select'. Ce n'est évidemment pas le cas et c'est pourquoi dans la colonne 3 du premier 'select' les dates sont transformées en texte.
L'exécution pure et dure de ce query donne (dans le cas d'un cadre de type ascii, ce qui s'obtient avec \pset linestyle a et \pset border 2):

Après avoir enlevé les 'substr', je complète mon query en ajoutant une colonne pour montrer les dates des opérations ainsi qu'une colonne qui contiendra les mentions 'SOUS-TOTAL' et 'TOTAL' car une troisième instruction 'SELECT' me fournira le total général.
Au final le query est le suivant:
select to_char(date_exec, 'MM TMMonth') AS mois,
'' as " ", date_exec::text,
montant
from bcard
where extract(year from date_exec) = 2013
UNION
select to_char(date_exec, 'MM TMMonth'),
'SOUS-TOTAL', '',
sum (montant) AS total
from bcard
where extract(year from date_exec) = 2013
group by 1, 2, 3
UNION
select '99', 'TOTAL', '', sum(montant)
from bcard
order by 1, 2, 3
Les colonnes correspondantes des différents 'select' doivent avoir le même type de données. Si la colonne 3 du premier 'select' contient des dates, il doit en être de même pour les autres 'select'. Ce n'est évidemment pas le cas et c'est pourquoi dans la colonne 3 du premier 'select' les dates sont transformées en texte.
L'exécution pure et dure de ce query donne (dans le cas d'un cadre de type ascii, ce qui s'obtient avec \pset linestyle a et \pset border 2):

Pour faire disparaître les numéros d'ordre il suffit de faire précéder l'exécution de
\o | awk '{print t=substr($0, 1, 2)substr($0, 6)}'
et ensuite pour rediriger l'output vers la sortie standard:
\o
(voir l'article précédant)
Mais je veux plus: je veux que les noms des mois soient visibles seulement dans les rangées 'SOUS-TOTAL'.
Cette fois je dois faire précéder l'exécution des instructions SQL de
\o | awk -f fichier.awk
où fichier.awk contient:
{
if ($0 ~ /[A-Z]/ && $0 !~/SOUS/)
{
if ($3 ~ /[éû]/)
if ($3 ~ /[éû]/)
$0=substr($0, 1, 5)" "substr($0, 16)
else
$0=substr($0, 1, 5)" "substr($0, 15)
}
}
t=substr($0, 1, 2)substr($0, 6)
print t
}
Et voilà ce que ça donne:

Quelques explications sur le code awk:
t contient la ligne lue ($0) dont on a retiré les caractères 3, 4, 5.
Pour faire disparaître le nom des mois, les caractères 6 à 14 de $0 sont, le cas échéant, remplacés par des espaces.
Certains noms de mois comprennent des caractères (é et û) qui sont codés sur 2 octets. Dans ce cas la reprise s'effectue à l'octet 16 au lieu de 15.
Prenons un exemple:
| 09 Septembre |
12345678901234567890
| 02 Février |
1234567901234567890
Dans le premier cas, l'espace devant la deuxième séparation se trouve à l'octet 15, mais à l'octet 16 dans l'autre cas car le 'é' de Février occupe les octets 7 et 8.
Je veux aussi que les rangées avec le mot 'SOUS-TOTAL' soient séparées des autres, ce qui peut être obtenu avec un fichier.awk contenant:
t contient la ligne lue ($0) dont on a retiré les caractères 3, 4, 5.
Pour faire disparaître le nom des mois, les caractères 6 à 14 de $0 sont, le cas échéant, remplacés par des espaces.
Certains noms de mois comprennent des caractères (é et û) qui sont codés sur 2 octets. Dans ce cas la reprise s'effectue à l'octet 16 au lieu de 15.
Prenons un exemple:
| 09 Septembre |
12345678901234567890
| 02 Février |
1234567901234567890
Dans le premier cas, l'espace devant la deuxième séparation se trouve à l'octet 15, mais à l'octet 16 dans l'autre cas car le 'é' de Février occupe les octets 7 et 8.
Je veux aussi que les rangées avec le mot 'SOUS-TOTAL' soient séparées des autres, ce qui peut être obtenu avec un fichier.awk contenant:
NR==3 {y=substr($0,1, 2)substr($0, 6)}
{
if ($0 ~ /[A-Z]/ && $0 !~/SOUS/)
{
if ($3 ~ /[éû]/)
if ($3 ~ /[éû]/)
$0=substr($0, 1, 5)" "substr($0, 16)
else
$0=substr($0, 1, 5)" "substr($0, 15)
}
}
t=substr($0, 1, 2)substr($0, 6)
if ($0 ~ /SOUS/)
{print y;print t;print y}
else
print t
}
En ligne 3, on sauvegarde la ligne de séparation qui sera imprimée avant et après les lignes "sous-total".
Et voilà:

.....

Si on utilise un style de ligne du type unicode (après exécution de \pset linestyle u), le fichier.awk précédent doit être adapté:
NR==3 {y=substr($0,1, 3)substr($0, 13)}
{
if ($0 ~ /[A-Z]/ && $0 !~/SOUS/)
{
if ($3 ~ /[éû]/)
$0=substr($0, 1, 7)" "substr($0, 18)
else
$0=substr($0, 1, 7)" "substr($0, 17)
}
if ($0 !~/[A-Za-z0-9]/)
t=substr($0,1, 3)substr($0, 13)
else
t=substr($0, 1, 4)substr($0, 8)
if ($0 ~ /SOUS/)
{print y;print t;print y}
else
print t
}
NR==3 {y=substr($0,1, 3)substr($0, 13)}
{
if ($0 ~ /[A-Z]/ && $0 !~/SOUS/)
{
if ($3 ~ /[éû]/)
$0=substr($0, 1, 7)" "substr($0, 18)
else
$0=substr($0, 1, 7)" "substr($0, 17)
}
if ($0 !~/[A-Za-z0-9]/)
t=substr($0,1, 3)substr($0, 13)
else
t=substr($0, 1, 4)substr($0, 8)
if ($0 ~ /SOUS/)
{print y;print t;print y}
else
print t
}
Les caractères du cadre sont cette fois codés sur 3 octets: enlever 3 morceaux de ligne du cadre = enlever 9 octets.
Dans le traitement il faut distinguer les lignes 100% cadre ($0 !~/[A-Za-z0-9]/) des autres.
(Un exemple beaucoup plus simple est développé dans l'article précédent )
Dans le traitement il faut distinguer les lignes 100% cadre ($0 !~/[A-Za-z0-9]/) des autres.
(Un exemple beaucoup plus simple est développé dans l'article précédent )
Ce qui donne:

Rappelons que le résultat peut-être envoyé dans un fichier avec:
\o | awk -fichier.awk > fichier.txt