Les fonctions PL/pgSQL étudiées dans les articles précédents envoyaient en sortie des rangées contenant les données d'une seule table. Nous allons maintenant travailler sur un exemple où ce n'est plus le cas.
Soient un ensemble de tables liées par des relations d'
intégrité référentielle telles que représentées sur ce schéma:
Les tables frcp, frdepartem et frregions sont présentées
ici. Il est question de la table service et de la table employés dans l'article relatif à l'
intégrité référentielle. Quant à la table gestion, elle a été introduite dans
cet article.
Le challenge consiste à construire une fonction donnant une liste contenant le matricule, le nom, le nom du département de résidence des employés d'un service donné, le nom du service étant transmis en tant que paramètre de la fonction.
Tout d'abord nous plaçons dans une variable code le code du service (service_id) tiré à partir de son nom fourni en input ($1):
SELECT service_id
INTO code
FROM services
WHERE dénomination = $1
Une fois le code récupéré, nous accédons via la table gestion aux matricules et aux noms grâce à un
join avec la table employés. Partant de la table employés nous pouvons atteindre le nom du département en effectuant des
joins avec les tables frcp et frdepartem.
Voici la requête qui sera utilisée:
SELECT a.matricule, a.nom, c.departem_nom
FROM employés a, frcp b, frdepartem c, gestion d
WHERE a.code_postal = b.code_postal
AND a.cp_seq = b.cp_seq
AND b.code_departem = c.departem_id
AND a.matricule = d.matricule
AND d.service = code
ORDER BY 3, 1
Cela étant, différentes possibilités s'offre à nous en ce qui concerne la fonction proprement dite.
Nous pouvons par exemple utiliser un curseur:
CREATE FUNCTION stat1services(text)
RETURNS SETOF refcursor
AS $$
DECLARE
code services.service_id%TYPE;
service alias FOR $1;
cursemp CURSOR (code text) IS
SELECT a.matricule, a.nom, c.departem_nom
FROM employés a, frcp b, frdepartem c, gestion d
WHERE a.code_postal = b.code_postal
AND a.cp_seq = b.cp_seq
AND b.code_departem = c.departem_id
AND a.matricule = d.matricule
AND d.service = code
ORDER BY 3, 1;
BEGIN
SELECT service_id
INTO code
FROM services
WHERE dénomination = service;
FOR empr IN cursemp (code) LOOP
RETURN NEXT empr;
END LOOP;
RETURN;
END;
$$ LANGUAGE 'plpgsql';
La variable empr est créée d'office et ne doit pas être déclarée. chaque rangée lue par le curseur lui est assignée. Le curseur est ouvert automatiquement avec l'instruction FOR.
Résultat:
EDIT: SETOF refcursor ne fonctionne plus. Il faut donc indiquer après SETOF un type correspondant aux rangées émises. Ce type doit être créé comme indiqué plus loin.
SELECT * FROM ... donnera alors un output plus agréable.
Cet output peut-être amélioré car la variable empr possède une sous-structure qui est définie au moment où une valeur lui est assignée:
CREATE FUNCTION stat11services(text)
RETURNS SETOF refcursor
AS $$
DECLARE
code services.service_id%TYPE;
service alias FOR $1;
cursemp CURSOR (code text) IS
SELECT a.matricule, a.nom, c.departem_nom AS département
FROM employés a, frcp b, frdepartem c, gestion d
WHERE a.code_postal = b.code_postal
AND a.cp_seq = b.cp_seq
AND b.code_departem = c.departem_id
AND a.matricule = d.matricule
AND d.service = code
ORDER BY 3, 1;
BEGIN
SELECT service_id
INTO code
FROM services
WHERE dénomination = service;
RETURN NEXT 'matr | nom | département';
RETURN NEXT '-----+--------------------------------+------------------------------------';
FOR empr IN cursemp (code) LOOP
RETURN NEXT empr.matricule || ' | ' || rpad(empr.nom, 30) || ' | ' || empr.département;
END LOOP;
RETURN;
END;
$$ LANGUAGE 'plpgsql';
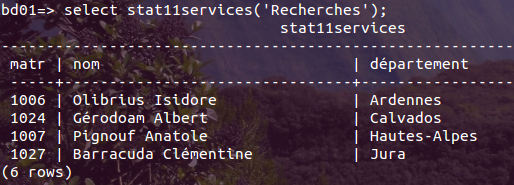
Regardons ce que ça donne:
EDIT: SETOF refcursor ne fonctionne plus: il faut donc procéder comme ci-après
L'idéal serait de pouvoir indiquer dans la clause RETURNS un type correspondant aux rangées émises. C'est facile quand les rangées émises proviennent d'une seule table, mais ce n'est pas le cas.
Il faut donc créer le type dont on a besoin:
CREATE TYPE emp AS
(matricule integer,
nom char(50),
département char(30))
Nous pouvons maintenant dans la définition de la fonction stat1services remplacer SETOF refcursor par SETOF emp.
Appelons stat12services la nouvelle fonction ainsi obtenue. SELECT * FROM permet alors d'avoir facilement un format de sortie nettement plus convivial:
On peut même se passer de déclarer un curseur:
CREATE FUNCTION stat2services(text)
RETURNS SETOF emp
AS $$
DECLARE
code services.service_id%TYPE;
service alias FOR $1;
empr RECORD;
BEGIN
SELECT service_id
INTO code
FROM services
WHERE dénomination = service;
FOR empr IN
SELECT a.matricule, a.nom, c.departem_nom
FROM employés a, frcp b, frdepartem c, gestion d
WHERE a.code_postal = b.code_postal
AND a.cp_seq = b.cp_seq
AND b.code_departem = c.departem_id
AND a.matricule = d.matricule
AND d.service = code
ORDER BY 3, 1
LOOP
RETURN NEXT empr;
END LOOP;
RETURN;
END;
$$ LANGUAGE 'plpgsql';
Si nous ne souhaitons pas créer un nouveau type, il est possible d'utiliser la clause
RETURNS TABLE associée à
RETURN QUERY:
CREATE FUNCTION stat3services(text)
RETURNS TABLE (matricule integer, nom character(50), département character(30))
AS $$
DECLARE
code services.service_id%TYPE;
service alias FOR $1;
BEGIN
SELECT service_id
INTO code
FROM services
WHERE dénomination = service;
RETURN QUERY SELECT a.matricule, a.nom, c.departem_nom
FROM employés a, frcp b, frdepartem c, gestion d
WHERE a.code_postal = b.code_postal
AND a.cp_seq = b.cp_seq
AND b.code_departem = c.departem_id
AND a.matricule = d.matricule
AND d.service = code
ORDER BY 3, 1;
END;
$$ LANGUAGE 'plpgsql';