Dans le billet précédent nous avons créé une base de données PostgreSQL. Nous y avons ajouté et chargé les tables
frregions: table des régions
frdepartem: table des départements
frcp: table des code postaux et des localités correspondantes
Ces trois tables sont liées par des relations d'intégrités différentielles qui garantissent que chaque localité est dans un département et chaque département dans une région.
frcp: table des code postaux et des localités correspondantes
Ces trois tables sont liées par des relations d'intégrités différentielles qui garantissent que chaque localité est dans un département et chaque département dans une région.
Après connexion à openoffice, on peut facilement sur base des tables frregions et frdepartem établir un rapport tel que celui-ci:

Le problème est que à l'origine (voir billet précédent), nous avons créé un toto tout puissant, quasiment l'égal de postgres, l'administrateur désigné de PostgeSQL. Nous devons d'abord lui enlever la qualité de superuser. Mais en outre, étant propriétaire-créateur, toto a tous les droits sur ces tables. On va donc procéder aux opérations suivantes:

Les commandes sont suffisamment explicites pour qu'on n'ait pas besoin d'en dire davantage.
Notons simplement toto a pu se retirer lui-même la qualité de superuser, mais il ne pourra pas faire machine arrière!
Notons simplement toto a pu se retirer lui-même la qualité de superuser, mais il ne pourra pas faire machine arrière!
La table des ressources humaines.
Comme indiqué un peu plus haut, nous avons encore besoin d'une table supplémentaire.
Nous allons par exemple créer la table entrh (ressources humaines de l'entreprise ent) à partir du fichier Centrh:
CREATE TABLE entrh
(matricule SERIAL PRIMARY KEY,
nom CHAR(50),
adresse char(50),
salaire money,
code_postal char(5),
cp_seq smallint,
FOREIGN KEY (code_postal,cp_seq) REFERENCES frcp)
;
(matricule SERIAL PRIMARY KEY,
nom CHAR(50),
adresse char(50),
salaire money,
code_postal char(5),
cp_seq smallint,
FOREIGN KEY (code_postal,cp_seq) REFERENCES frcp)
;
Un matricule sera créé automatiquement pour chaque personne figurant dans la table de manière à former une clef primaire et l'ensemble code_postal, cp_seq devra pointer obligatoirement vers une rangée de la table frcp (à moins d'avoir la valeur NULL).
Bien sûr, il s'agit d'une table toute simple qui bafoue d'ailleurs allègrement le principe consistant à ne pas mélanger les données signalétiques aux autres. Elle est uniquement destinée à illustrer notre propos (au départ ce devait être seulement une table des adresses). Nous ne développons pas ici un véritable projet de gestion des ressources humaines (ce qui nécessiterait plusieurs dizaines de tables).
C'est parti:

Nous voudrions aussi que la série de matricules ne commence pas par 1:

Le salaire est une donnée confidentielle: attribuons le privilège select de manière telle que cette donnée ne soit pas accessible::

Le groupe des gestionnaires du personnel.
Il reste à créer le groupe des personnes qui va s'occuper de la gestion du personnel et à lui attribuer les droits qui conviennent sur la table entrh en tenant compte de ce que le matricule ne peut pas être mis à jour. Par contre, il faut un update sur la séquence entrh_matricule_seq afin de permettre la création des matricules:
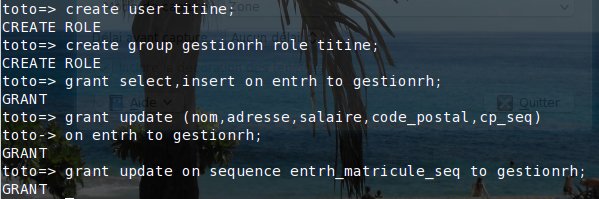
Pour l'instant le groupe de gestion (gestionrh) ne comprend qu'une personne, titine qui a juste été créée pour l'occasion. Par la suite, on pourra facilement en ajouter d'autres (ou en retirer) avec la commande alter group:
ALTER GROUP groupname ADD USER username [, ... ] ALTER GROUP groupname DROP USER username [, ... ]
Notons qu'il ne faut pas confondre l'instruction CREATE USER qui a créé titine, avec la commande createuser utilisée précédemment pour créer toto (voir billet précédent).
Tentative de connexion en tant que gestionnaire.
Tentative de connexion en tant que gestionnaire.
Afin de vérifier si les personnes du groupe gestionrh ont les droits suffisants, tentons de connecter titine à la base de données toto avec la commande psql. La syntaxe de cette commande est:
psql [option...] [dbname [username]]
dbname et username sont par défaut égal au nom de l'utilisateur qui exécute la commande.
Donc si je ne suis pas titine, je dois préciser les deux paramètres:

Ça ne fonctionne pas. Essayons en activant le terminal interactif psql en tant que toto: on peut y modifier sa connexion avec la méta-commande \connect:
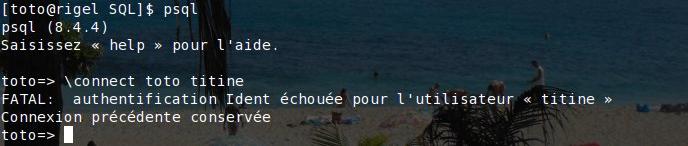
Nouvel échec. Comment procéder pour que toto puisse se connecter facilement en tant que titine? La solution se trouve dans le fichier de configuration pg_hba.conf.
Nouvel échec. Comment procéder pour que toto puisse se connecter facilement en tant que titine? La solution se trouve dans le fichier de configuration pg_hba.conf.
Les fichiers pg_hba.conf et pg_ident.conf
Le chemin vers les fichiers de configuration de PostgreSQL, et notamment pg_hba.conf, dépend de la distribution.
Exemples de tels chemins:
Exemples de tels chemins:
/var/lib/pgsql/data/
/etc/postgresql/8.4/main/
Sur notre machine le fichier de configuration pg_hba.conf par défaut est le suivant:# TYPE DATABASE USER CIDR-ADDRESS METHOD
# "local" is for Unix domain socket connections only
local all all ident
# IPv4 local connections:
host all all 127.0.0.1/32 md5
# IPv6 local connections:
host all all ::1/128 md5
# "local" is for Unix domain socket connections only
local all all ident
# IPv4 local connections:
host all all 127.0.0.1/32 md5
# IPv6 local connections:
host all all ::1/128 md5
Nous y constatons la présence de deux méthodes d'authentification md5 (par mot de passe crypté) et ident. D'autres méthodes sont possibles.
La méthode d'authentification Ident fonctionne en prenant le nom de l'utilisateur du système d'exploitation et en s'en servant comme nom d'utilisateur PostgreSQL. L'authentification échouera si l'utilisateur PostgreSQL obtenu par Ident n'existe pas, ou encore s'il est différent du nom que l'on transmet en paramètre dans la commande de connexion. C'est le cas ici. Alors comment procéder pour résoudre notre problème? Nous pourrions modifier le fichier pg_hba.conf comme ceci:
# TYPE DATABASE USER CIDR-ADDRESS METHOD
# "local" is for Unix domain socket connections only
# IPv4 local connections:
host all all 127.0.0.1/32 md5
# IPv6 local connections:
host all all ::1/128 md5
# "local" is for Unix domain socket connections only
local all titine md5
local all all ident# IPv4 local connections:
host all all 127.0.0.1/32 md5
# IPv6 local connections:
host all all ::1/128 md5
Pour se connecter en tant que titine, il suffit de fournir son mot de passe. Il n'y a aucun lien établi avec l'utilisateur du système d'exploitation qui demande la connexion. titine peut même ne pas exister au niveau du système d'exploitation. Et le mot de passe alors? Attention, il s'agit d'un mot de passe défini dans PostgreSQL. Mais le but de la manoeuvre étant que toto puisse se connecter facilement en tant que titine, ce n'est pas vraiment la bonne solution.
Non, la solution est de passer par l'intermédiaire du fichier pg_ident.conf afin de définir un mappage entre les utilisateurs PostgreSQL et les utilisateurs du système d'exploitation. Modifions ce fichier pour qu'il contienne ceci:
# MAPNAME SYSTEM-USERNAME PG-USERNAME
map01 toto titine
map01 titine titine
map01 toto titine
map01 titine titine
La première ligne permet à toto de se connecter en tant que titine. Il faut aussi que titine puisse se connecter, d'où l'existence de la deuxième ligne.
Il s'agit maintenant d'établir un lien entre pg_hba.conf et ce fichier pg-ident.conf, comme ceci:
# TYPE DATABASE USER CIDR-ADDRESS METHOD
# "local" is for Unix domain socket connections only
local all titine ident map=map01
# "local" is for Unix domain socket connections only
local all titine ident map=map01
local all all ident
# IPv4 local connections:
host all all 127.0.0.1/32 md5
# IPv6 local connections:
host all all ::1/128 md5
# IPv4 local connections:
host all all 127.0.0.1/32 md5
# IPv6 local connections:
host all all ::1/128 md5
On pourrait dans la ligne ajoutée remplacer titine par @group01, où group01 est un fichier qui se trouve dans le même dossier que pg_hba.conf et contenant le mot titine. Attention si on ajoute à group01 d'autres utilisateurs sans modifier pg_ident.conf en conséquence, ils ne pourront plus se connecter.
D'autres méthodes d'authentification sont possibles:
trust: n'importe qui peut se connecter en utilisant n'importe quel nom d'utilisateur PostgreSQL.
reject: éventuellement utile pour rejeter certains postes clients.
et beaucoup d'autres encore....
Pour que les changements introduits soient pris en compte, il faut recharger le serveur:
# service postgresql reload
Insertion dans la table des ressources humaines
Nous avons préparé une instruction SQL d'insertion d'une rangée dans la table entrh. Celle-ci se trouve dans le fichier insert01:
insert into entrh
values (default, 'Gédéon Théodore','Avenue des oiseaux rares, 28','2456,3'::money,'02200',3)
;
values (default, 'Gédéon Théodore','Avenue des oiseaux rares, 28','2456,3'::money,'02200',3)
;
Cette instruction doit être exécutée par titine puisque nous voulons vérifier que les membres du groupe gestionrh ont les droits qui conviennent pour pouvoir travailler. Le problème de connexion toto -> titine étant résolu, tout devrait bien se passer:

?? Pour la connexion c'est OK, mais pour le reste...En fait, toto, propriétaire de la table frcp droit récupérer son droit d'update sur cette table. Cela permet au système de tenir un lock sur la table frcp pendant la durée de la transaction d'insertion afin de garantir l'intégrité référentielle des données. Il ne faudrait pas que quelqu'un supprime (ou modifie) la rangée de frcp vers laquelle va pointer la nouvelle rangée insérée dans entrh. Il est donc illusoire de penser que l'on peut rendre la table frcp read only pour toto. Par contre pour titine, elle le reste bel et bien (heureusement).
Procédons:

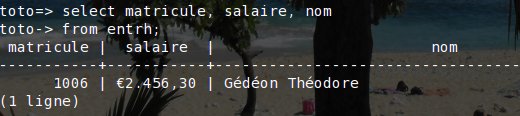
Oui, mais lors du premier essai, au moment de l'erreur sur frcp, la séquence qui sert pour les matricules avait déjà été mise à jour.
Or il n'y a jamais de retour en arrière (rollback) pour les séquences.
Bon, le contenu de ce billet est déjà bien assez consistant.
Nous avions annoncé que nous allions montrer comment se connecter avec openoffice.
Et si on en reparlait dans un prochain billet?