Une expression régulière est une suite de caractères ordinaires et de méta-caractères, utilisée en tant que critère de sélection.
Un caractère ordinaire correspond uniquement à lui-même alors qu'un méta-caractère possède une signification spéciale.
Le méta-caractère « . »
Comme premier exemple de méta-caractère, considérons le point « . ». Celui-ci correspond à n'importe quel caractère (sauf le caractère de fin de ligne).
Illustrons notre propos à l'aide d'un petit fichier col que nous créons:
$ echo -e 'calepin\nclavier\ncolis\n1 col\ncol blanc\nc\047est cool.\nalcool\ncoool!' | tee col
calepin
clavier
colis
1 col
col blanc
c'est cool.
alcool
coool!
calepin
clavier
colis
1 col
col blanc
c'est cool.
alcool
coool!
L'utilisation de l'option -e avec la commande echo fait que \n est interprété en tant que caractère « fin de ligne » et \047 en tant qu'apostrophe. Le flux généré par echo n'est pas envoyé directement vers la sortie standard (l'écran), mais il transite d'abord par le programme tee qui en fait une copie dirigée vers col. On peut ainsi visionner directement le contenu du fichier nouvellement créé.
Nous allons maintenant utiliser grep pour afficher les éléments (lignes) du fichier qui contiennent une sélection correspondant à l'expression régulière indiquée:
$ grep 'c.l.' col
calepin
colis
col blanc
calepin
colis
col blanc
Le premier « . » de l'expression régulière « c.l. » implique l'existence d'un caractère entre le c et le l, ce qui élimine « clavier ». Le deuxième « . » impose que le l doit être suivi par un caractère, ce qui élimine «1 col ».
Le méta-caractère « * »
Il correspond à un ensemble de 0 à n occurrences du caractère précédant:
$ grep 'co*l' col
clavier
colis
1 col
col blanc
c'est cool.
alcool
coool!
clavier
colis
1 col
col blanc
c'est cool.
alcool
coool!
clavier est conservé (0 occurrence de o entre c et l).
Le méta-caractère « + »
Il correspond à un ensemble de 1 à n occurrences du caractère précédant, ce qui devrait cette fois éliminer « clavier »:
$ grep 'co+l' col
Aucun retour! Explication: « + » est par défaut un caractère ordinaire. Mais il existe un opérateur, l'opérateur d'échappement, qui appliqué à « + » lui permet d'échapper à sa (misérable) condition de caractère ordinaire, et le transforme en méta-caractère. Ce caractère est représenté par « \ » (backslash).
$ grep 'co\+l' col
colis
1 col
col blanc
c'est cool.
alcool
coool!
colis
1 col
col blanc
c'est cool.
alcool
coool!
Par rapport à l'output précédant, clavier est bien éliminé.
Le méta-caractère « ? »
Celui-ci correspond à au plus 1 occurrence du caractère précédant.
Attention « ? » doit lui être aussi sublimé en méta-caractère par la magie de l'opérateur d'échappement:
$ grep 'co\?l' col
clavier
colis
1 col
col blanc
clavier
colis
1 col
col blanc
Le caractère précédant un méta-caractère peut être lui-même un méta-caractère:
$ grep 'c.\?l' col
calepin
clavier
colis
1 col
col blanc
calepin
clavier
colis
1 col
col blanc
Le méta-caractère correspondant à l'opérateur OR
Il est obtenu par sublimation de « | »:
$ grep 'bla\|cla' col
clavier
col blanc
clavier
col blanc
Les méta-caractères accolades
Il servent à donner des précisions sur le nombre d'occurrences désirées du caractère précédant. Attention: ils ne sont pas reconnus d'emblée comme méta-caractère (à moi l'opérateur d'échappement). Voici quelques exemples d'utilisation. On désire:
exactement 3 o:
$ grep 'co\{3\}l' col
coool!
coool!
entre 1 et 2 o:
$ grep 'co\{1,2\}l' col
colis
1 col
col blanc
c'est cool.
alcool
colis
1 col
col blanc
c'est cool.
alcool
au minimum 2 o:
$ grep 'co\{2,\}l' col
c'est cool.
alcool
coool!
c'est cool.
alcool
coool!
au maximum 2 o:
$ grep 'co\{,2\}l' col
grep: décompte de répétition mal formé
grep: décompte de répétition mal formé
Un bug ? En tout cas avec sed utilisé en tant qu'émulateur de grep, ça fonctionne:
$ sed -n '/co\{,2\}l/p' col
clavier
colis
1 col
col blanc
c'est cool.
alcool
clavier
colis
1 col
col blanc
c'est cool.
alcool
Avec grep, il faut mettre un 0 devant la virgule.
Les classes de caractères
Une classe de caractères est définie à l'aide d'une liste entre crochets reprenant tous les caractères à inclure. Cette liste peut elle même comprendre une plage de caractères: deux caractères séparés par un tiret.
Exemples:
[0123456789] ou [0-9]: tous les chiffres
$ grep '[0-9]' col
1 col
1 col
[prv]: les lettres p, r, v
[a-z]: toutes les lettres minuscules
[a-zA-Z]: toutes les lettres minuscules et majuscules.
$ grep '[a-zA-Z]\{4\}n' col
calepin
calepin
La commande sélectionne des chaînes comprenant un « n » précédé de 4 lettres. « col blanc » n'est pas retenu car l'espace compris entre « col » et « blanc » n'est pas une lettre.
Si le premier caractère qui suit le crochet d'ouverture est un « ^ », la classe ainsi définie comprend tous les caractères et toutes les plages de caractères qui ne sont pas repris dans liste.
Exemples:
[^0-9]: pas les chiffres
[^a-z]: pas les lettres minuscules.
$ grep –-color '[^aco]l' col
col blanc
col blanc
On a sélectionné les chaînes contenant un « l » qui n'est précédé ni d'un « a », ni d'un « c » et ni d'un « o ». L'option –-color permet la mise en évidence de la sélection correspondant à l'expression régulière: « ol » n'est pas sélectionné mais bien « bl ».
$ grep –color 'l[^a-z]' col
col blanc
c'est cool.
coool!
col blanc
c'est cool.
coool!
On retient ici les éléments du fichier col qui contiennent un « l » suivi d'un caractère qui n'est pas une lettre minuscule. «1 col » (le 4ième élément qui vient après « colis ») n'est pas retenu car il n'est suivi par rien. Nous avons surligné la sélection en vert pâle pour montrer que l'espace entre col et blanc en fait partie.
Les classes de caractères prédéfinies
On peut trouver à l'intérieur des crochets de définition d'une classe, des classes de caractères prédéfinies. Leur nom est explicite:
[:digit:], [:alpha:], [:alnum:], [:space:],[:punct], [:cntrl:], [:lower:], [:upper] etc
Exemple:
$ grep '[[:punct:]]' col
c'est cool.
Coool!
c'est cool.
Coool!
Attention, il y a deux paires de crochets:
les crochets qui servent à définir une classe de caractère (en rouge ci-dessous)
les crochets qui font partie du nom d'une classe prédéfinie (en vert ci-dessous)
$ grep '[[:digit:]p.]' col
calepin
1 col
c'est cool.
calepin
1 col
c'est cool.
Donc ici, on a recherché les chaînes avec un chiffre, un « p », ou un point.
Tiens, le point n'est pas un méta-caractère qui représente n'importe quel caractère?
Non, car dans une classe de caractères, il n'y a pas de méta-caractère.
La classe [:space:]
Intéressons-nous à la classe [:space:]. Il s'agit d'une classe de caractère qui comprend non seulement les espaces, mais aussi les caractères de tabulation et les retours chariot:
$ grep 'col[[:space:]]' col
col blanc
col blanc
Fournissons à grep un fichier col adapté à windows, dont les lignes contiennent un caractère de contrôle \r (retour chariot) précédant le caractère \n (fin de ligne). Comme \r appartient à la classe [:space:], col de « 1 col » est maintenant lui aussi suivi d'un caractère appartenant à cette classe:
$ sed 's/$/\r/' col | grep 'col[[:space:]]'
1 col
col blanc
1 col
col blanc
(La transformation par sed d'un fichier unix en fichier dos est expliquée dans un autre billet.)
Considérons maintenant l'output suivant:
$ echo -e 'abc\t1\ndef 2'
abc 1
def 2
abc 1
def 2
(\t est interprété en tant que caractère de contrôle tabulation.)
Filtrons maintenant cet output en imposant comme critère de sélection: une lettre suivie d'un espace (en fait un caractère de la classe [:space:]) et un chiffre:
$ echo -e 'abc\t1\ndef 2' | grep --color '[a-z][[:space:]][0-9]'
abc 1
abc 1
La deuxième ligne est éliminée car entre la lettre f et le chiffre 2, il y a plusieurs espaces. Par contre le \t est bien considéré comme un seul espace.
La classe [:cntrl]
Considérons la classe [:cntrl:], classe des caractères de contrôle. La question qui se pose est: le caractère « fin de ligne » (\n) en fait-il partie?
Faisons un test.
$ echo -e 'abc\t1\ndef 2' | grep '[[:cntrl:]]1'
abc 1
abc 1
Le caractère de contrôle avant le 1 (\t) est bien détecté, mais pas le caractère fin de ligne (\n) qui suit le 1:
$ echo -e 'abc\t1\ndef 2' | grep '1[[:cntrl:]]'
Concluant? Non, car grep (comme sed et awk) enlève le caractère \n à la lecture de chaque ligne et le remet lors du renvoi de la ligne vers la sortie standard.
On doit procéder autrement pour montrer que ce caractère de contrôle « fin de ligne » appartient bien à la classe [:cntrl:]. Pour ce faire nous allons utiliser sed:
$ sed -n '/cl/{N;s/[[:cntrl:]]//;p}' col
claviercolis
claviercolis
Lorsqu'une ligne contenant « cl » est rencontrée, les actions suivantes (entre les accolades et séparées par des point-virgules) sont effectuées à l'intérieur de la commande sed:
N ajoute le caractère \n puis la ligne « colis » à la ligne « clavier » qui vient d'être lue
s remplace le premier caractère de contrôle rencontré par rien, donc le supprime
p imprime le tout.
« clavier » et « colis » sont maintenant collés: cela montre que \n appartient à [:cntrl:].
D'ailleurs si on enlève l'action s le caractère fin de ligne qui sépare « clavier » et « colis » est toujours présent:
$ sed -n '/cl/{N;p}' col
clavier
colis
clavier
colis
Classes de caractères prédéfinies hors crochets
Certaines classes de caractères prédéfinies sont désignées par un caractère promu au grade de méta-caractère par la grâce de l'opérateur d'échappement:
\W ensemble des caractères qui ne peuvent pas se trouver dans un mot:
$ grep 'co\+l\W' col
col blanc
c'est cool.
coool!
col blanc
c'est cool.
coool!
(Les caractères de ponctuation ne font pas partie des mots.)
\w: ensemble des caractères qui peuvent se trouver dans un mot. Attention: \w n'est pas l'équivalent de [a-zA-Z0-9] car on doit y ajouter l'underscore. Mettons cette différence en évidence.
$ echo -e 'colis\ncol_dur' | grep --color 'col\w'
colis
col_dur
colis
col_dur
Les deux candidats passent le test.
$ echo -e 'colis\ncol_dur' | grep --color 'col[a-zA-Z0-9]'
colis
colis
col_dur est recalé!
Tiens, si on ajoutait recalé au fichier:
$ echo 'recalé' >> col
Aie! Un caractère accentué. Les problèmes vont commencer.
Le problème des caractères accentués.
Vérifions si \w contient les caractères accentués:
$ grep --color 'cal\w' col
calepin
calepin
Et recalé?
Il doit y avoir un problème avec la localisation puisque \w ne comprend pas les caractères accentués.
Pourtant le terminal est en UTF-8:
$ printf '\xc3\xa9\n'
é
é
tout comme le fichier:
$ grep recal col | od -An -tx1
72 65 63 61 6c c3 a9 0a
72 65 63 61 6c c3 a9 0a
et locale est en accord:
$ locale | grep CTYPE
LC_CTYPE="fr_FR.UTF-8"
LC_CTYPE="fr_FR.UTF-8"
Essayons avec [a-z]:
$ grep --color 'cal[a-z]' col
calepin
recalé
calepin
recalé
où avec [:alpha:]:
$ grep 'cal[[:alpha:]]' col
calepin
recalé
calepin
recalé
Là, ça fonctionne. Il semble que ce soit \w qui pose problème.
sed lui donne le bon résultat avec \w:
$ sed -n '/cal\w/p' col
calepin
recalé
calepin
recalé
mais pas awk:
$ awk '/cal\w/' col
calepin
calepin
Essayons ceci:
$ export LC_CTYPE=fr_FR
(alors que nous sommes en UTF-8, mais bon...).
Bingo avec \w, ça fonctionne pour grep et awk:
$ grep 'cal\w' col
calepin
recalé
$ awk '/cal\w/' col
calepin
recalé
calepin
recalé
$ awk '/cal\w/' col
calepin
recalé
ce qui est quand même assez étonnant.
Par contre maintenant avec [a-z], ça foire (logiquement) pour grep et sed, mais pas pour awk!
Avec [:alpha:], c'est toujours bon.
Tout ça mérite un petit tableau pour plus de clarté:

KO (sur fond rouge): le caractère accentué (ici le « é ») n'est pas reconnu comme faisant partie de la classe indiquée en tête de colonne.
OK: tout va bien!
Sur fond vert: la valeur de LC_CTYPE normale (héritée de la localisation).
Sur fond orange: valeur de LC_CTYPE ne correspondant à la localisation car on est effectivement en UTF-8.
Notons que ce tableau peut varier d'une distribution à l'autre. Bref, il convient d'être toujours attentif quant on doit traiter avec des caractères accentués.
Les bordures de mot.
Recherchons les « col » qui sont en bordure de mot, plus précisément à la fin d'un mot. N'avons-nous pas déjà la solution avec:
$ grep 'col\W' col
col blanc
col blanc
Non, car le 4ième élément, «1 col », n'est pas retenu. La bonne méthode consiste à utiliser le méta-caractère \b, bordure de mot:
$ grep 'col\b' col
1 col
col blanc
1 col
col blanc
On peut aussi utiliser le méta-caractère bordure de fin de mot \>:
$ grep 'col\>' col
1 col
col blanc
1 col
col blanc
De même, pour une sélection en début de mot, \W ne convient pas:
$ grep '\Wco\{2,\}' col
c'est cool.
c'est cool.
mais bien \b:
$ grep '\bco\{2,\}' col
c'est cool.
coool!
c'est cool.
coool!
ou le méta-caractère bordure de début de mot \< :
$ grep '\
c'est cool.
coool!
c'est cool.
coool!
(alcool est éliminé car cool n'est pas en début de ce mot).
Précisons comme on pouvait s'y attendre que la signification de \B, est NON bordure de mot:
$ grep 'col\B' col
colis
$ grep '\Bco\{2,\}' col
alcool
colis
$ grep '\Bco\{2,\}' col
alcool
Les candidats éliminés précédemment sont cette fois retenus.
Notons que tous ces méta-caractères qui détectent la bordure des mots, souffrent de la même maladie que \w (si elle existe):
$ grep 'c.l\>' col
1 col
col blanc
recalé
1 col
col blanc
recalé
Comme « é » n'est pas reconnu en tant que caractère constitutif d'un mot, recalé n'est pas un mot, mais bien recal et cal colle à la bordure de ce mot. Donc cal est sélectionné ce qui entraîne l'affichage de la ligne « recalé »
Les méta-caractères d'ancrage ^ et $
^ impose un ancrage en début de chaîne.
$ grep '^.\{2\}a' col
clavier
clavier
recherche des chaînes avec un « a » en troisième position. En effet, il doit y avoir 2 caractères entre le début de la chaîne et a.
Sans ancrage on obtient ceci:
$ grep -–color '.\{2\}a' col
clavier
col blanc
recalé
clavier
col blanc
recalé
$ impose un ancrage en fin de chaîne.
$ grep 'a.\{2\}$' col
col blanc
calé
col blanc
calé
recherche des chaînes avec un a en antépénultième position.
Sans ancrage:
$ grep -–color 'a.\{2\}' col
calepin
clavier
col blanc
alcool
recalé
calepin
clavier
col blanc
alcool
recalé
Les parenthèses de mémorisation.
L'élément de la sélection correspondant à la partie de l'expression régulière comprise dans la n ième paire de méta-parenthèses est conservé dans /n pour un usage ultérieur.
echo 'Pistolets 2:,87x2 = 1,74 euros' | sed 's/\([^0-9]\)\(,[0-9]\{2\}[^0-9]\)/\10\2/'
Pistolets 2:0,87x2 = 1,74 euros
Pistolets 2:0,87x2 = 1,74 euros
La sélection (sur fond vert pâle) est divisée en deux parties de couleurs différentes: la première correspond à l'expression régulière limitée par la paire de méta-parenthèses bleues (un non chiffre), la deuxième à l'expression régulière entourée par les méta‑parenthèses rouges (virgule + 2 chiffres suivi d'un non chiffre). La chaine de remplacement \10\2 est donc constituée de la partie 1 de la sélection + « 0 » + la partie 2.
Les expressions régulières étendues.
La multiplication des opérateurs d'échappement peut nuire à la lisibilité d'une expression régulière. Dans ce cas, il est préférable d'utiliser une expression régulière étendue. La seule différence avec les expressions régulières de base est que les caractère ?, +, {, } |, (, et ) sont par défaut des méta-caractères. On indique à grep d'utiliser des expressions régulières étendues avec l'option -E. Pour sed, c'est l'option -r:
$ echo 'Pistolets 2:,87x2 = 1,74 euros' | sed -r 's/([^0-9])(,[0-9]{2}[^0-9])/\10\2/'
Pistolets 2:0,87x2 = 1,74 euros
$ grep -E 'bla|cla' col
clavier
col blanc
Pistolets 2:0,87x2 = 1,74 euros
$ grep -E 'bla|cla' col
clavier
col blanc
awk lui utilise d'office des expressions régulières étendues:
$ awk '/bla|cla/' col
clavier
col blanc
clavier
col blanc
S'échapper vers l'ordinaire.
De nombreuses personnes rêvent d'échapper à l'ordinaire de leur vie afin de mener un jour une vie de milliardaire. Mais l'inverse existe aussi: de grandes vedettes rêvent d'échapper à la notoriété afin de pouvoir mener (en tout cas pour quelques jours) une petite vie tranquille et ordinaire. L'opérateur d'échappement permet les deux: transformer un caractère ordinaire en méta-caractère, mais il permet aussi à un méta-caractère de (re)devenir un caractère ordinaire:
$ grep '\.$' col
c'est cool.
c'est cool.
(Le « . » est cette fois un caractère ordinaire.)
Le sens dans lequel agit l'opérateur d'échappement peut varier suivant que l'on a affaire à une expression régulière étendue ou pas:
promotion de « + » au grade (envié) de méta-caractère:
$ echo -e 'co+l\ncol' | grep 'co\+l'
col
col
dégradation de « + » qui redevient un caractère ordinaire:
$ echo -e 'co+l\ncol' | grep -E 'co\+l'
co+l
Expressions régulières dans les traitements de texte
Certains traitement de textes supportent l'emploi d'expressions régulières dans la fonction « Rechercher ». C'est le cas d'openoffice.
Il faut d'abord cocher la cas adéquate:

Voici quelques exemples.
Recherche de 3 caractères maximum entre c et l:

La sélection doit terminer un mot:
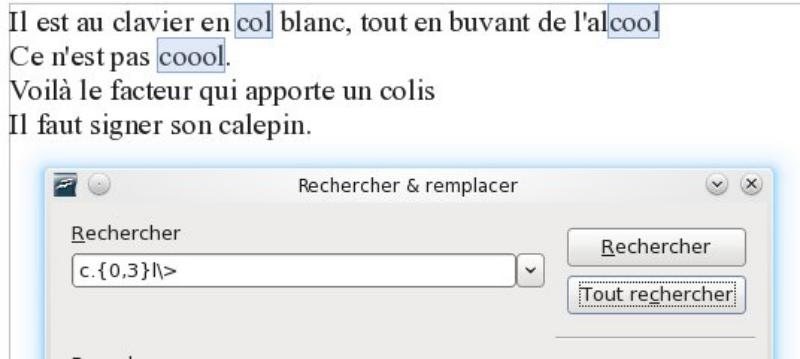
La sélection doit se trouver en fin de ligne:

Comme le montrent les exemples, openoffice travaille avec des expressions régulières étendues.
Utilisation avec SQL
Les base de données modernes (MySQL, PostgreSQL...) permettent l'emploi d'expressions régulières dans les instructions SQL.