Le problème qui se pose.
Intéressons-nous à la table entrh déjà considérée précédemment.
Intéressons-nous à la table entrh déjà considérée précédemment.
Elle contient les colonnes suivantes:
colonne | type |
-------------+---------------+
matricule | integer |
nom | character(50) |
adresse | character(50) |
salaire | money |
code_postal | character(5) |
cp_seq | smallint |
Nous aimerions changer le type de la colonne salaire de money à numeric(11,2).
Pourquoi changer?
Parce que le type money est obsolète depuis longtemps.
Faux: le type money est dé-obsolétisé (undeprecated) depuis la version 8.3 de PostgreSQL.
Parce que après connexion d'openoffice à notre base de donnée en utilisant JDBC, une erreur se produit à la lecture de la table entrh:
 Mais il nous est loisible d'utiliser un autre pilote que JDBC, le pilote SDBC intégré à openoffice (sous forme d'une extension), ce qui permet une connexion sans couche externe supplémentaire.
Mais il nous est loisible d'utiliser un autre pilote que JDBC, le pilote SDBC intégré à openoffice (sous forme d'une extension), ce qui permet une connexion sans couche externe supplémentaire.
Parce que on VEUT utiliser JDBC (cette fois, c'est imparable).
Le problème qui se pose est qu'il n'est pas possible de convertir le type salaire en numéric:
Pourquoi changer?
Parce que le type money est obsolète depuis longtemps.
Faux: le type money est dé-obsolétisé (undeprecated) depuis la version 8.3 de PostgreSQL.
Parce que après connexion d'openoffice à notre base de donnée en utilisant JDBC, une erreur se produit à la lecture de la table entrh:
Parce que on VEUT utiliser JDBC (cette fois, c'est imparable).
Le problème qui se pose est qu'il n'est pas possible de convertir le type salaire en numéric:
toto=> select salaire::numeric
toto-> from entrh
toto-> limit 1;
ERREUR: ne peut pas convertir le type money en numeric
LIGNE 1 : select salaire::numeric
^
toto-> from entrh
toto-> limit 1;
ERREUR: ne peut pas convertir le type money en numeric
LIGNE 1 : select salaire::numeric
^
Premières investigations
Par contre le convertir en type texte ne pose aucun problème:
toto=> select salaire::text
toto-> from entrh
toto-> limit 1;
salaire
-----------
€2.458,53
(1 ligne)
En suite, on peut passer du type texte au numérique. Pas quel que soit le contenu bien sûr, et pas pour '€2.458,53' :
toto=> select salaire::text::numeric(11,2)
toto-> from entrh
toto-> limit 1;
ERREUR: syntaxe en entrée invalide pour le type numeric : « €2.458,53 »
toto-> from entrh
toto-> limit 1;
ERREUR: syntaxe en entrée invalide pour le type numeric : « €2.458,53 »
Voici un exemple de contenu pour lequel ça fonctionne:
toto=> select '2458.53'::numeric(11,2);
numeric
---------
2458.53
(1 ligne)
numeric
---------
2458.53
(1 ligne)
La solution
Nous allons donc d'abord transformer la colonne "salaire" en colonne de type texte:
Nous allons donc d'abord transformer la colonne "salaire" en colonne de type texte:
toto=> alter table entrh
toto-> alter salaire type text;
ALTER TABLE
ALTER TABLE
Ensuite il s'agit de mettre la chaîne "salaire" au format qui convient pour que la conversion vers le type numeric(11,2) soit acceptée:
toto=> update entrh
toto-> set salaire = regexp_replace(salaire, '[€.]', '', 'g');
Nous rencontrons de nouveau une fonction qui utilise les expressions régulières, la précédente étant regexp_matches. Le premier argument de cette nouvelle fonction regexp_replace est la chaîne qui sera sera traitée. Le deuxième argument est l'expression régulière (en bleu) servant à sélectionner une ou plusieurs parties de la chaîne fournie en input. Ensuite vient la chaîne de remplacement qui se substituera aux différentes sélections et finalement les options. Ici, la chaîne de remplacement est vide: chacun des éléments de la classe [€.] s'il est rencontré, est remplacé par rien, donc supprimé. L'option 'g' demande que tous les remplacements possibles soient effectués. Sans cette option, seul le € initial disparaîtrait.
Vérifions le résultat:
toto=> select salaire
toto-> from entrh
toto-> limit 1;
salaire
---------
2458,53
(1 ligne)
toto-> from entrh
toto-> limit 1;
salaire
---------
2458,53
(1 ligne)
Il reste maintenant à remplacer la virgule par un point. On peut procéder comme ceci (pour varier les plaisirs):
toto=> update entrh
toto-> set salaire = overlay(salaire placing '.' from char_length(salaire) - 2);
toto-> set salaire = overlay(salaire placing '.' from char_length(salaire) - 2);
ou comme cela:
toto=> update entrh
toto-> set salaire = regexp_replace(salaire, ',', '.')
toto-> ;
toto-> set salaire = regexp_replace(salaire, ',', '.')
toto-> ;
Vérifions:
toto=> select salaire
toto-> from entrh
toto-> limit 1;
salaire
---------
2458.53
(1 ligne)
toto-> from entrh
toto-> limit 1;
salaire
---------
2458.53
(1 ligne)
Et pour terminer:
toto=> alter table entrh
toto-> alter salaire type numeric(11,2);
ERREUR: la colonne « salaire » ne peut pas être convertie vers le type numeric
toto-> alter salaire type numeric(11,2);
ERREUR: la colonne « salaire » ne peut pas être convertie vers le type numeric
Grrrr!
En fait, il faut procéder comme ceci
toto=> alter table entrh
toto-> alter salaire type numeric(11,2)
toto-> using salaire::numeric(11,2)
toto-> ;
ALTER TABLE
toto-> alter salaire type numeric(11,2)
toto-> using salaire::numeric(11,2)
toto-> ;
ALTER TABLE
Je veux une vue!
C'est merveilleux: nous pouvons maintenant afficher la table entrh dans notre outil graphique connecté à PostgeSQL via JDBC puisque qu'elle ne comprend plus de colonne de type money.
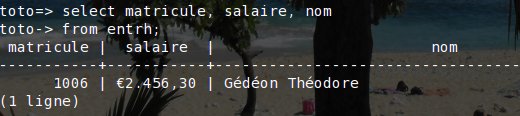
Mais maintenant dans un tableau tel que celui-ci (obtenu depuis un terminal psql):
 ou dans un tableau openoffice, l'affichage du salaire n'est plus vraiment satisfaisant: on a le point comme séparateur décimal et pas de séparateur de millier. Pour retrouver l'ancien affichage, il nous est loisible de créer une vue ne contenant pas la colonne salaire mais une colonne salaire_d définie comme dans l'instruction suivante:
ou dans un tableau openoffice, l'affichage du salaire n'est plus vraiment satisfaisant: on a le point comme séparateur décimal et pas de séparateur de millier. Pour retrouver l'ancien affichage, il nous est loisible de créer une vue ne contenant pas la colonne salaire mais une colonne salaire_d définie comme dans l'instruction suivante:
C'est merveilleux: nous pouvons maintenant afficher la table entrh dans notre outil graphique connecté à PostgeSQL via JDBC puisque qu'elle ne comprend plus de colonne de type money.
Mais maintenant dans un tableau tel que celui-ci (obtenu depuis un terminal psql):
toto=> select salaire,
toto-> regexp_replace(salaire::text, E'\\.', ',')::money as salaire_d
toto-> from entrh
toto-> limit 1;
salaire | salaire_d
---------+-----------
2458.53 | €2.458,53
(1 ligne)
toto-> regexp_replace(salaire::text, E'\\.', ',')::money as salaire_d
toto-> from entrh
toto-> limit 1;
salaire | salaire_d
---------+-----------
2458.53 | €2.458,53
(1 ligne)
La syntaxe qui apparaît dans la fonction regexp_replace mérite une explication:
Le premier argument doit être une chaîne de caractère, mais le salaire dans entrh est maintenant un nombre: c'est pourquoi il est converti en texte. Dans le deuxième argument, celui qui fournit l'expression régulière utilisée, le E indique que la chaîne qui suit contient des caractères d'échappement à traiter comme tel.
Le premier argument doit être une chaîne de caractère, mais le salaire dans entrh est maintenant un nombre: c'est pourquoi il est converti en texte. Dans le deuxième argument, celui qui fournit l'expression régulière utilisée, le E indique que la chaîne qui suit contient des caractères d'échappement à traiter comme tel.
Mais pourquoi doubler le backslash (\)?
Le test suivant donnera l'explication:
toto=> select E'\\.'as test;
test
------
\.
(1 ligne)
Le premier backslash (en rouge) est l'opérateur d'échappement qui agit sur le deuxième backslash et le transforme en caractère ordinaire. Le résultat est une suite de deux caractères ordinaires. En effet dans une chaîne SQL, le point est un caractère ordinaire. Cette suite constitue notre expression régulière, deuxième argument de la fonction regexp_replace. Dans cette expression régulière, le backslash survivant est de nouveau un opérateur d'échappement qui agit sur le méta-caractère point pour le transformer en caractère ordinaire. Celui-ci est ensuite remplacé par une virgule.
Donc nous créons la vue ventrh à partir du fichier Cventrh dont voici le contenu.
create view ventrh
as
select matricule, nom, adresse,
regexp_replace(salaire::text, E'\\.', ',')::money as salaire_d,
code_postal, cp_seq
from entrh;

C'est bon, ça fonctionne, mais PAS dans notre outil graphique utilisé avec JDBC: nous avons exactement la même erreur que précédemment.
La solution pour avoir un affichage convenable des montants monétaires, sans utilisation du CAST text::money, est d'utiliser la fonction to_char:
toto=> select salaire, to_char(salaire, '9G999G999D99') as salaire_t,
toto-> regexp_matches(to_char(salaire, '9G999G999D99'), E' \\d') as salaire_m,
toto-> regexp_replace(to_char(salaire, '9G999G999D99'), E' \\d', E'€\\&') as salaire_d
toto-> from entrhm
toto-> limit 2;
salaire | salaire_t | salaire_m | salaire_d
----------+---------------+-----------+----------------
2458.53 | 2.458,53 | {" 2"} | € 2.458,53
13587.00 | 13.587,00 | {" 1"} | € 13.587,00
(2 lignes)
La colonne salaire_t, t pour texte, nous montre le résultat de la fonction to_char.
La colonne salaire_m, m pour matché (!), nous donne la sélection du salaire-texte correspondant à l'expression régulière ' \d', un espace suivi d'un chiffre: \d est une notation abrégée pour la classe [0-9].
La colonne salaire_d, d pour displayable (!!), nous donne le résultat final. Dans la chaîne de remplacement '€\&', \& représente la totalité de la sélection, ce qui explique le blanc entre le symbole monétaire € et le montant proprement dit. Ce n'est pas plus mal. Pour éliminer ce blanc, il suffit d'utiliser les parenthèses mémorisantes et de mettre \1 au lieu de \& dans la chaîne de remplacement. En effet, \1 représente dans la chaine de remplacement, non pas toute la sélection, mais la partie de celle-ci qui est en rapport avec la partie de l'expression régulière encadrée par les parenthèses mémorisantes:
toto=> select salaire,
toto-> regexp_replace(to_char(salaire, '9G999G999D99'), E' (\\d)', E'€\\1') as salaire_d
toto-> from entrhm
toto-> limit 2;
salaire | salaire_d
----------+---------------
2458.53 | €2.458,53
13587.00 | €13.587,00
(2 lignes)
Modifions notre fichier Cventrh pour qu'il contienne ceci:
drop view ventrh;
create view ventrh
as
select matricule, nom, adresse,
regexp_replace(to_char(salaire, '9G999G999D99'), E' (\\d)', E'€\\1') as salaire_d,
code_postal, cp_seq
from entrh;
create view ventrh
as
select matricule, nom, adresse,
regexp_replace(to_char(salaire, '9G999G999D99'), E' (\\d)', E'€\\1') as salaire_d,
code_postal, cp_seq
from entrh;
Procédons et vérifions:

Voilà qui est parfait.
Et dans les formulaires?
Dans les formulaires aussi, l'abandon du type money nous fait perdre le bel affichage des montants monétaires:

Et une vue ne pouvant pas être directement mise à jour, mieux vaut ne pas en utiliser.
Cependant le problème peut-être réglé relativement facilement:
Cliquer sur la zone de saisie du montant, la touche CTRL étant maintenue enfoncée.
Dans la barre d'outils de gauche, choisir 'Contrôle':


Et voilà le résultat: